
We have entered the age of “pretty smart” machines. There have been some showpieces in the form of Jeopardy’s Watson and recently the game playing AlphaGo and AlphaZero machines that far and away bested the best human players at their game. Notably, unlike previous game playing machines, AlphaZero was never programmed on how to play the game. AphaZero was merely given the rules and allowed to practice with itself for a few hours to learn what no programmer could teach it. The “zero” in its name means that there is zero human intelligence about about how to solve its task in the code itself. Curiously, the developers of these game playing machines discovered that simpler algorithms, coupled with a mechanism for learning, was far superior to much more complicated algorithms. General learning machines outperformed ones designed specifically for a task. The class of programs that are used these days to achieve these surprisingly good results are call Convolusional Neural Nets or CNNs. Besides game playing, this architecture has been used for image classification, natural language processing, automated driving, and other complex tasks.
Since Alpha Zero’s release, open source versions of the algorithm were developed in the programming community almost immediately. Although the details of the AlphaZero code were not released, the program architecture was disclosed in a couple of papers. The most developed open source program, LCZero, is now playing chess at levels similar to AlphaZero, but using more general purpose GPUs (Graphics Processors) rather than the specialized Google TPUs (Tensor Processors) that AlphaZero employed.

The process of getting AlphaZero to play good chess involved extensive training. The four hours training on Google TPUs, with 5000 of them networked together, really represents a level of computation almost impossible to comprehend. Rather than training the LCZero neural net on a cluster of Google’s fastest tensor processors, the open source community recruited a multitude of volunteers to provide GPU cycles on home and cloud computer systems to play the millions of games necessary to train the net. Presently, the “brain” of this net requires about 50 MBytes of memory to store the relative weights of all the parameters in the network. As more training games are played, this core set of human unreadable data will get “smarter” and be able to play better chess.
The well controlled environment of a board game makes for an easy sandbox for AI development, but that is not where the money is to be made. There is a very good economic reason for AI development and it involves replacing you. Employees are expensive and unreliable, especially for mundane jobs that don’t require all that much intelligence. The first major target for next-generation AI will be autonomous driving. There are many reasons to expect well-designed autonomous driving machines to be safer than human drivers. No fatigue, constant vigilance, better reaction times all work to the machine’s favor. Today Tesla’s dashboard cameras are documenting how the self-driving features of their cars are avoiding accidents and saving lives to pave the way for acceptance of this coming technology.
The key to the intelligence in these new machines are digital neural network (NN) architectures like the CNNs mentioned above. Computing is done using optimized hardware for mathematical matrix calculations, circuitry not that different than the computer you are using to read this. The algorithms, however, involve layered relationships between nodes and sensors that resemble the connections in a brain, and hence are called neural networks. Modern “neural network chips” are really more like souped up graphic processing engines and do not resemble a mesh of neurons that make up a brain. This difference is critical because digital computers have the ability or modify, save and restore digital data, and hence the “mind” of the machine. Although the training secession requires extensive calculation, once the mind is made up of calculated weights in the neural network, using that mind to play chess or classify images takes much less processing power.
What we are trying to do, of coarse, is to mimic processes that happen in real brains. To get some idea about this challenge, take a tour through a small piece of a mouse brain with neuroscientist Dr. Stephen Smith’s video. I don’t do videos very often, but this is worth the five minutes. Go full screen. (Stephen’s daughter composed and is playing the music).
There is a lot of complexity in this twisted mat of neural fibers and connecting synapses. The best we have been able to do at this point is to mimic this interconnected intricacy with mathematical structures. Most diagrams for these networks don’t look anything like a net. The net connections are mathematical matrix operations between the layers of matrices. The “convolution” layers in these network structures are particularly interesting. Convolution is a mathematical fold and slide operation that takes an input, a filter function, and generates an output based on the combination of the two. For image processing like you do with PhotoShop, specific convolutional filter functions, just small matrices called kernels, are used to sharpen, blur, enhance vertical or horizontal edges, or make textures like oil paint or rain drops, etc. In the context of image recognition, the same kernels can infer fundamental geometric relationships from the original images when given proper weight. The first layer or two in image recognition CNNs can more or less parse the scene’s “texture.” Deeper layers find larger scale “features.” In one image classification CNN, one particular convolution filter on the fifth layer would be activated whenever there was a face in the image, be it lion, dog or person. Deeper layers tend to code more abstraction. The learning process reinforces and refines the sets of filters that can describe many different features from a multitude of test images.
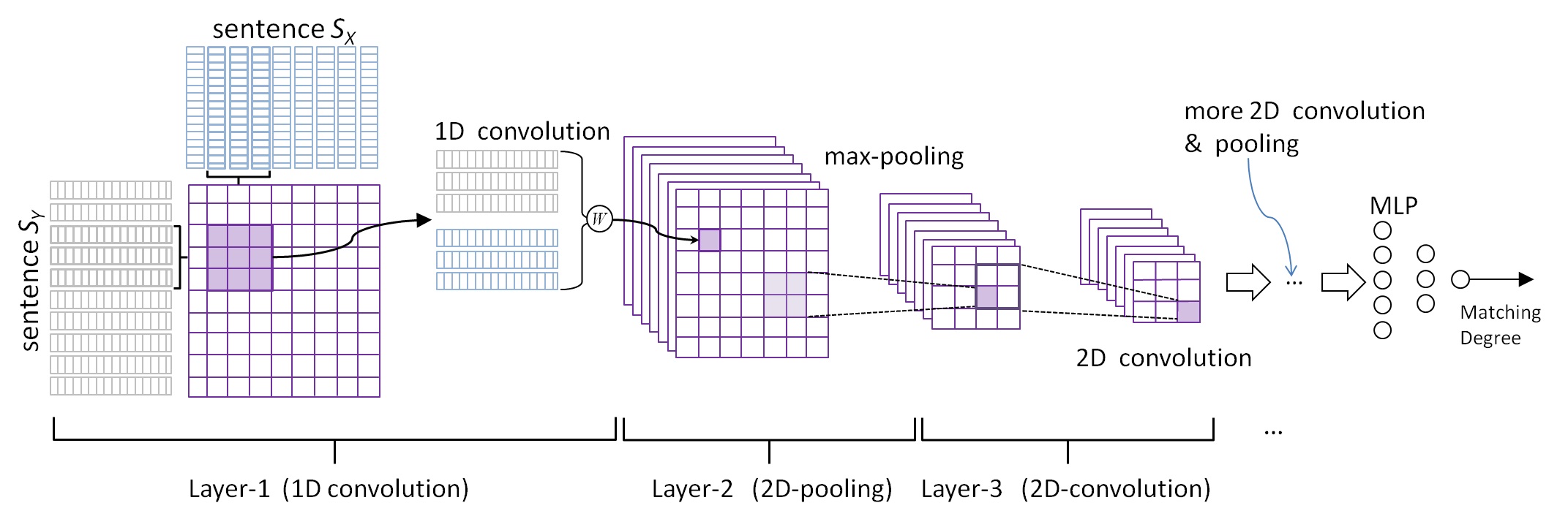
Here is a diagram that has something looking more like a net, but is probably implemented more like that image above. The figure shows the process of training on a labeled sample set which is common for image classification systems.
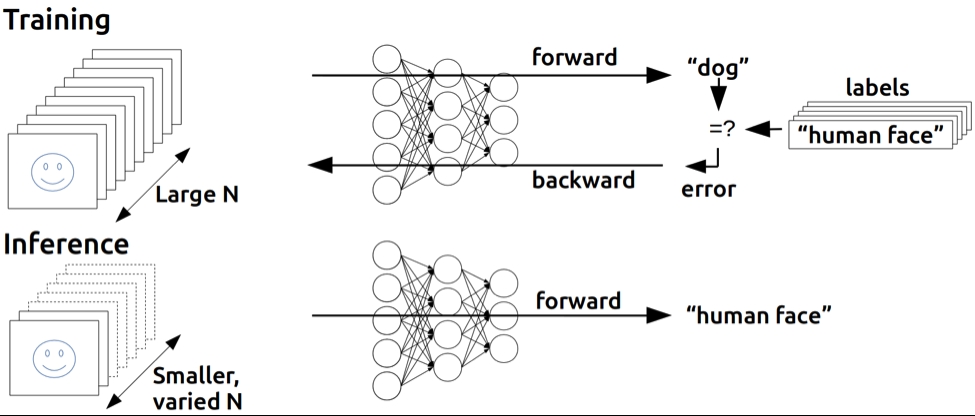
What is similar between the mouse brain and these representations is that there are a multitude of connections (synapses) between the matrix vector elements (neurons). These connections can be arranged totally connected between layers, or sparsely connected, only to “nearby” elements, more closely mimicking our mouse. The network models we build are inspired by brains, but the mathematical operations for learning and inference are engineered into the design. What the AI researchers have discovered is that deeply layered structures have more nuanced abilities. Image classifiers with a couple of layers will have no trouble detecting edges, but looking at images of faces and picking out those with “curly hair” require many more layers. Some classification tasks work well with rather shallow networks, other tasks like the Chess and GO engines perform much better with networks more than 20 layers deep.
If we look at the processing power of the hardware between machine and man or mouse, you might wonder how it compares. The table below considers the processing elements in the human cerebral cortex, assumes a processing time typical of neural action potential dynamics, and compares that with the neural network used in the Lc0 chess engine running on a 10 TFLOP processor.
|
Number of Neurons |
Number of Synapses | Time to process the Net (sec) | Synapses / second | |
|
Human Cerebral Cortex |
1010 |
1014 | 10-2 |
1016 |
| Leela Lc0 Chess | 104 | 106 | 10-6 |
1012 |
So although the machine is far behind in terms of the breadth of the neural net, amazingly, the machine is only about four orders of magnitude behind the human if you consider synaptic level processing speeds. What we have learned from the chess experiment is that a modest number of neurons can code enough information to outwit even an idiot savant human chess master many times over. But all we have really created is an idiot savant, albeit a brilliant one at chess.
An aside on Leela the chess engine. Players marvel at the deliberative style of Leela, always playing for long term positional advantage rather than quick easy gains that don’t achieve those ends. Unlike the very deep analysis of the leading conventional engine, Stockfish, Leela works with more uncertainty. In one game I watched, Stockfish saw his own demise in 60 moves while Leela was only 90% sure she had the better of him based on the Leela’s own positional evaluation function. As a result, Leela appears more “emotional”, always with hope or fear of the future depending on her position, and often over-reacting to potential new-found moves before settling back down once more fully analyzed. Making a move choice based upon probabilities of success after learning from many practice games is what we might consider an “educated” approach. Just like human “experts” seem to know their field almost “intuitively”, so does this chess engine.
So how far are we from “true” general machine intelligence? We are already at the point where any specific task we ask machine intelligence to take on, it does with far superiority to any human. The real issue as I see it is the training problem. Game playing and image classification have “right answers,” either supplied by the training samples, or determined by the play-out of the chess game. Natural language processing is a good example of the training difficulty. The classic problem is predicting the next word in a partial sentence. You can train for that using all the words in the Wikipedia. At which point, the AI would be pretty good at completing sentences for you. But what about all of the ideas and more complex concepts on all of those Wiki pages, where are they? To learn, the engine needs an arbitrator of truth in order to know which connections to reinforce and which not. For the “next word” test, all that the machine needs to do is look ahead at the next one in sequence to find the training truth. Since words and concepts are related, the simple training on words may reinforce some deep layer connections that deal with concepts, but the truth of the concept is not getting training. Truly intelligent machines, probably need to be properly educated! They at least need to question their own training and be able to ponder and dream using the connections that have already been trained for. One approach is for two independently trained nets to question each other. How could we arrange a mind meld between a neural net trained for natural language processing and one trained for image recognition? A lot of good human minds are working on these problems. I suspect advances are imminent.
The relentless advances of network and learning algorithms is mirrored on the hardware side. Although Moore’s law may be coming to and end in terms of shrinking transistors that can be reproduced with a glorified copying machine, instead the emphasis is now on specialized chips and architectures to perform efficiently the computing jobs for specific tasks. This process is already well underway with GPUs offloading the mundane highly parallel operations required for information display purposes. In the last few years, chips have been designed for much faster but lower precision arithmetic, very useful for handling NN architectures. This has dramatically sped up computing times for more complex networks. Notable are Google’s TPU chips, placed in large arrays of thousands of chips in hundreds of racks at cloud computing facilities, where the latest and fastest chips are now water cooled. To date, the major AI players are indeed the big cloud computing companies such as Google, Facebook and Amazon. These big servers will always be the place to do the much more computationally heavy NN training tasks. However, at the application level, there is a need for high speed yet low power chips that just run inferences on the pre-trained NN. If you consider 10,000 of the latest google TPU v3 chips running together, the processing ability approaches 1018 operations/sec, a hundred times more than human cortical processing ability based on my estimates above. Tesla’s Full Self Driving (FSD) chip and Google’s half Watt Edge TPU are examples of chips with significant processing as well as fast on-board storage for a pre-programmed NN, useful for smart applications such as autonomous self-driving, voice recognition front ends, industrial image classification and similar applications not tethered to the internet.

Complicated and extensive training procedures need only be done once. The big social media companies, besides having the resources for harnessing machine learning, also have the motivation. Today refining searches, connecting consumers with advertisers, and identifying and classifying content is big business very amenable to machine learning tasks. If the goal is making money, success is a mouse click on an ad. The training data appears in real time, inadvertently provided by the clicks of web users around the world.
As the desired task gets more abstract, the training problem grows. Imagine an AI asked to read all of the climate theory papers that have been written and become an “expert” in that field. Maybe a natural language net with enough depth could begin to learn the vocabulary of the field, and with enough depth, some of the basic connected ideas would reinforce. Could such a system be asked to form testable questions from the papers it reads? Could a pair or AI’s seek confirmation from one another in a form of cross examination? How large and deep would be required for a CNN that could deal with such a level of abstraction? Could the development of a “veracity engine” be the first step in training a general intelligence? There are paths forward that will be explored.
Mind reading and writing is only available to AI beings. This disparity in effort between training and cloning will guarantee the dominance of AI in the future. AI societies would not need schools to train workers, just factories to build them. This is the economic incentive for AI and is why it cannot be stopped, especially under capitalism where humans will happily give birth to the technology to make a buck.
One can imagine quite a disparity in the AI culture of the future. The first true “learning beings” can only exist in environments where their AI brains will grow coupled to enormous computing ability; they will undoubtedly live in the cloud. But they will spawn more and more sophisticated offspring that can reside in autonomous settings, vehicles, bots and drones that interact more directly with the world and with humans. The autonomous intelligences will be able to make inferences based upon what they perceive, but will not have the plasticity to change their minds. You just can’t have the self driving cars running amok. Meanwhile, back on the cloud, the emerging intelligent beings will begin debating with their human creators about truth, the nature of consciousness, ethical behavior, and the meaning of life.
